
การศึกษา
พลิกโฉมวิเคราะห์ไวยากรณ์บาลียุค AI นักวิชาการชี้ “ประสาทเทียมเชิงสัญลักษณ์” คือทางออกใหม่
ติดตามข่าวด่วน กระแสข่าวบน Facebook คลิกที่นี่

การบูรณาการปัญญาประดิษฐ์ (AI) กับการวิเคราะห์ไวยากรณ์ภาษาบาลี กำลังก้าวขึ้นเป็นพรมแดนวิจัยสำคัญของโลกวิชาการ ท่ามกลางความท้าทายเชิงโครงสร้างของภาษาคลาสสิกตระกูลอินโด-อารยัน ที่มีระบบสัณฐานวิทยาและวากยสัมพันธ์ซับซ้อนสูง นักวิจัยชี้ชัดว่า แนวทาง “ประสาทเทียมเชิงสัญลักษณ์” (Neurosymbolic AI) คือกระบวนทัศน์ใหม่ที่อาจสร้างสมดุลระหว่างความแม่นยำทางไวยากรณ์กับพลังการเรียนรู้ของโครงข่ายประสาทเทียม
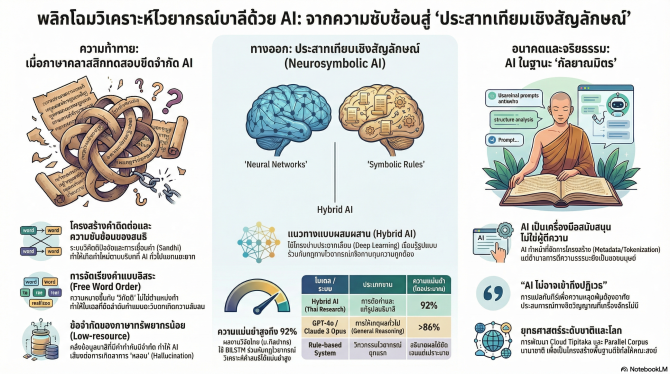
โครงสร้างภาษาบาลี: บททดสอบขั้นสุดยอดของ AI
ภาษาบาลีในฐานะรากฐานคัมภีร์พระไตรปิฎก อรรถกถา และฎีกา มีลักษณะเป็นภาษาคำติดต่อ (Highly inflected language) เต็มไปด้วยระบบสมาส (Samasa) และสนธิ (Sandhi) ที่ทำให้คำจำนวนมากกลายเป็น “คำใหม่ตามบริบท” (Out-of-vocabulary) สำหรับระบบคอมพิวเตอร์
การแยกคำ (Tokenization) ซึ่งเป็นขั้นพื้นฐานของการประมวลผลภาษาธรรมชาติ (NLP) จึงเผชิญอุปสรรคอย่างรุนแรง โดยเฉพาะเมื่อต้องแก้สนธิหลายชั้นพร้อมกัน หรือรับมือกับโครงสร้างจัดเรียงคำอิสระ (Free word order) ที่ความหมายขึ้นกับ “วิภัตติ” ไม่ใช่ตำแหน่งคำ
นักวิจัยระบุว่า โมเดลสมัยใหม่ที่อาศัย Positional Encoding อาจสับสนเมื่อต้องวิเคราะห์ประโยคที่ไม่ยึดรูปแบบประธาน-กริยา-กรรมแบบตะวันตก
วิวัฒนาการ NLP: จากกฎเกณฑ์สู่ Deep Learning
ในช่วงแรก การพัฒนาเครื่องมือวิเคราะห์บาลีใช้ระบบอิงกฎเกณฑ์ (Rule-based systems) และวิศวกรรมไวยากรณ์ (Grammar engineering) จุดแข็งคืออธิบายผลลัพธ์ได้ชัดเจน แต่เปราะบางต่อคำใหม่และใช้ทรัพยากรผู้เชี่ยวชาญสูง
ต่อมาแนวทางสถิติและ Machine Learning เช่น SVM และ CRF เข้ามาแทนที่ โดยงานศึกษาบางชิ้นพบว่า SVM มีความแม่นยำสูงกว่า 95% ในการจำแนกคำ อย่างไรก็ตาม เมื่อก้าวสู่ยุค Deep Learning ด้วย RNN และ LSTM ก็ยังติดปัญหา “Low-resource language” เนื่องจากคลังข้อมูลบาลีแบบมีคำกำกับ (Annotated corpora) ยังจำกัด
Hybrid AI: ความสำเร็จจากงานวิจัยไทย
ความก้าวหน้าสำคัญเกิดขึ้นเมื่อศูนย์ความเป็นเลิศด้าน AI และ NLP ของมหาวิทยาลัยศิลปากร พัฒนาระบบตัดคำบาลีแบบผสมผสาน ใช้ BiLSTM วิเคราะห์ตำแหน่งแยกคำ แล้วใช้กฎไวยากรณ์แก้ไขรูปคำให้ถูกต้องตามหลักดั้งเดิม
การทดสอบกับคำสนธิกว่า 6,000 คำจากคัมภีร์ธัมมปทัฏฐกถา ให้ผลแม่นยำกว่า 92% สะท้อนศักยภาพของแนวทางประสาทเทียมเชิงสัญลักษณ์ที่ควบคุมความถูกต้องด้วยตรรกะทางภาษาศาสตร์
LLMs กับข้อจำกัดเชิงโครงสร้าง
แม้โมเดลภาษาขนาดใหญ่ (LLMs) เช่น GPT-4o, Claude-3, Llama และ Gemini จะมีความสามารถข้ามภาษาโดดเด่น แต่ผู้เชี่ยวชาญเตือนถึงปัญหา “Low-resource bias” และพฤติกรรม Overcorrection รวมถึง Hallucination ในการแปลคัมภีร์
งานประเมินชี้ว่า GPT-4o และ Claude 3 Opus มีคะแนนความแม่นยำสูงกว่า 86% ในงานให้เหตุผลทั่วไป ขณะที่ตระกูล Llama 3.1 โดดเด่นด้านการตรวจจับข้อผิดพลาด แต่ยังมีความเสี่ยงต่อการเบี่ยงเบนจากต้นฉบับเมื่อต้องตีความปรัชญาเชิงลึก
นักวิชาการจำนวนหนึ่งจึงเห็นพ้องว่า LLM ควรทำหน้าที่สนับสนุนเชิงโครงสร้าง มากกว่าการเป็น “ผู้แปลชี้ขาด”
โครงการระดับโลกและโครงสร้างพื้นฐานดิจิทัล
เวทีนานาชาติกำลังเร่งสร้างคลังข้อมูลภาษาคลาสสิกโดยเฉพาะ โครงการ MITRA ภายใต้ความร่วมมือของ UC Berkeley พัฒนา Parallel Corpus เชื่อมโยงบาลี สันสกฤต จีนเชิงพุทธ และทิเบต พร้อมโมเดลปรับแต่งบนสถาปัตยกรรม Gemma
ขณะเดียวกัน แพลตฟอร์ม SuttaCentral ยืนยันนโยบาย “100% AI-free” สำหรับงานแปลพระสูตร โดยเน้นการควบคุม Metadata และระบบติดตามการแก้ไขผ่าน Git เพื่อรักษาความบริสุทธิ์ของข้อมูล
ไทยเร่งยุทธศาสตร์ AI-พระไตรปิฎก
ในประเทศไทย กระทรวงดิจิทัลเพื่อเศรษฐกิจและสังคม ร่วมกับมหาวิทยาลัยมหามกุฏราชวิทยาลัย ลงนามพัฒนาระบบ AI เพื่อการเผยแผ่พระพุทธศาสนา พร้อมผลักดันโครงการ ThaiLLM โดยสถาบันข้อมูลขนาดใหญ่ (BDI) เพื่อสร้างโมเดลภาษาแห่งชาติที่เข้าใจบริบทไทย
โครงการ “Cloud Tipitaka” ของมหาวิทยาลัยมหาจุฬาลงกรณราชวิทยาลัย ยังมุ่งย้ายฐานข้อมูลพระไตรปิฎกขึ้นระบบคลาวด์ เปิดทางให้ AI ใช้ประมวลผลคำถาม-คำตอบทางธรรมะอย่างเป็นระบบ
มิติทางจริยธรรม: AI เป็นกัลยาณมิตร ไม่ใช่ผู้ตีความ
ข้อถกเถียงสำคัญอยู่ที่คำถามว่า เครื่องจักรสามารถตีความสภาวะธรรมแทนมนุษย์ได้หรือไม่ นักแปลพระสูตรหลายรายยืนยันว่า การแปลคัมภีร์เพื่อการหลุดพ้นต้องอาศัย “ปฏิเวธ” ซึ่ง AI ไม่อาจมีได้
กระบวนทัศน์ที่ได้รับการยอมรับมากที่สุดจึงคือ การให้ AI ทำหน้าที่ “เครื่องมือสนับสนุนทางโครงสร้าง” เช่น การแยกคำสนธิ-สมาส การทำพจนานุกรม และการจัดการ Metadata ขณะที่อำนาจการตีความยังคงอยู่กับมนุษย์
บทสรุป: สมดุลระหว่างคอมพิวเตอร์กับจิตวิญญาณ
ผู้เชี่ยวชาญสรุปตรงกันว่า โครงสร้างอันวิจิตรของภาษาบาลีคือบททดสอบขีดจำกัดของ AI ยุคปัจจุบัน แนวทาง Hybrid และ Neurosymbolic AI คือคำตอบที่สมดุลที่สุดในเชิงเทคนิค ส่วนในเชิงจริยธรรม การรักษาอำนาจการตีความไว้กับมนุษย์คือหลักประกันความถูกต้องของพระสัทธรรม
การประมวลผลภาษาบาลีในยุคปัญญาประดิษฐ์จึงไม่ใช่เพียงประเด็นเทคโนโลยี หากเป็นภารกิจร่วมกันของนักวิทยาการคอมพิวเตอร์ นักอักษรศาสตร์ และคณะสงฆ์ ในการธำรงรักษาคลังปัญญาของโลกให้สถาพรและทรงคุณค่าในยุคดิจิทัล.
ติดตามข่าวด่วน กระแสข่าวบน Facebook คลิกที่นี่
หน้าแรก » การศึกษา
Top 5 ข่าวการศึกษา ![]()
- พลิกโฉมวิเคราะห์ไวยากรณ์บาลียุค AI นักวิชาการชี้ “ประสาทเทียมเชิงสัญลักษณ์” คือทางออกใหม่ 25 ก.พ. 2569
- เปิดตัว “Buddharoid” พระสงฆ์ปัญญาประดิษฐ์แห่งญี่ปุ่น พึ่งทางใจยุคดิจิทัล ท่ามกลางวิกฤตศรัทธาและการเปลี่ยนผ่านครั้งใหญ่ของพุทธศาสนา 25 ก.พ. 2569
- มทร.ธัญบุรี เชิดชู ‘สุดยอดนักวิจัย’ ประจำปี 2568 ดันงานวิจัยนวัตกรรมไทย สู่เวทีโลก มหาวิทยาลัยเทคโนโลยีราชมงคลธัญบุรี (มทร.ธัญบุรี) จัดพิธีเชิดชูเกียรตินักวิจัย ประจำปี 2568 25 ก.พ. 2569
- วิศวกรรมชีวการแพทย์ ม.รังสิต จัดค่ายเรียนรู้อุปกรณ์ฉุกเฉินทางการแพทย์ช่วงเทศกาลสงกรานต์ 25 ก.พ. 2569
- กรมศิลปากรรับมอบโบราณวัตถุจากสหรัฐอเมริกา 53 รายการ 25 ก.พ. 2569
ข่าวในหมวดการศึกษา ![]()
![]() "ลิณธิภรณ์" ชี้ความรุนแรงที่เกิดขึ้นในสังคม สะท้อนวิกฤตสุขภาพจิตคนไทย เสนอ 3 มาตรการ เร่งแก้แต่ต้นเหตุ 15:40 น.
"ลิณธิภรณ์" ชี้ความรุนแรงที่เกิดขึ้นในสังคม สะท้อนวิกฤตสุขภาพจิตคนไทย เสนอ 3 มาตรการ เร่งแก้แต่ต้นเหตุ 15:40 น.- เวทีโลกถกอนาคต AGI ชี้ “ตรรกวิทยาเชิงพุทธ” อาจคลี่วิกฤตญาณวิทยา AI 12:16 น.
- ผดุงปัญญา จัดคอนเสิร์ต“THE MASK SINGER Season 2” โชว์ศักยภาพดนตรีนักเรียน ม.6 17:26 น.
- "มมร" จัดเสวนาวิชาการ “วันมาฆบูชา 2569” ชูพุทธสันติวิธีกับอนาคตการอยู่ร่วมกันของสังคมไทย 16:47 น.
- เปิดมรรคาใหม่ AI โลกวิชาการชี้ “นาคารชุนโมเดล” พลิกสถาปัตยกรรมหุ่นยนต์–จริยธรรมยุคอุตสาหกรรม 5.0 16:31 น.
